This section deals with the advanced topic of SkXML. You should only tackle this section if you have are completely confident with the DPS System, and have some prior technical knowledge of XML and query languages. Here you will learn:
| ► | How and why we refer to a 'Corpus'. |
| ► | How to access the SkXML Search Screen. |
| ► | Understanding the Default Results Screen. |
| ► | Detailed examples and tables describing the SkXML query language. |
| ► | About Keyword-in-Context views. |
| ► | About other results views. |
SkXML is a sophisticated query language that combines powerful text-searching facilities with an awareness of a the data's XML structure. DPS uses SkXML in two ways:
| 1. | As an option when searching for entries |
| 2. | As an 'evidence finder' for searching corpora |
This section concentrates on the second use - as 'evidence finder' - where SkXML's power is fully revealed.
In terms of language and writing, a 'corpus' refers to a body of work or knowledge relating to a particular subject. The DPS System treats any DPS project as a corpus in that it considers the project to be the whole body of work. Many of these projects will be dictionaries that have been compiled using DPS, but others might be dedicated corpora; DPS does not distinguish between the two types. Using SkXML, you can search any, some, or all of the projects loaded on your DPS server.
Accessing the SkXML Search Screen
| 1. | In any DPS screen, click the SkXML Box button. |
![]() Tip: it is often advisable to open SkXML in a new browser tab or window; right-clicking on the SkXML Box button should give you the option to do this.
Tip: it is often advisable to open SkXML in a new browser tab or window; right-clicking on the SkXML Box button should give you the option to do this.
| 2. | You might be asked for a username and password; if so, use the same ones you use to log in to the DPS Website. Once you are logged in your screen will look something like this: 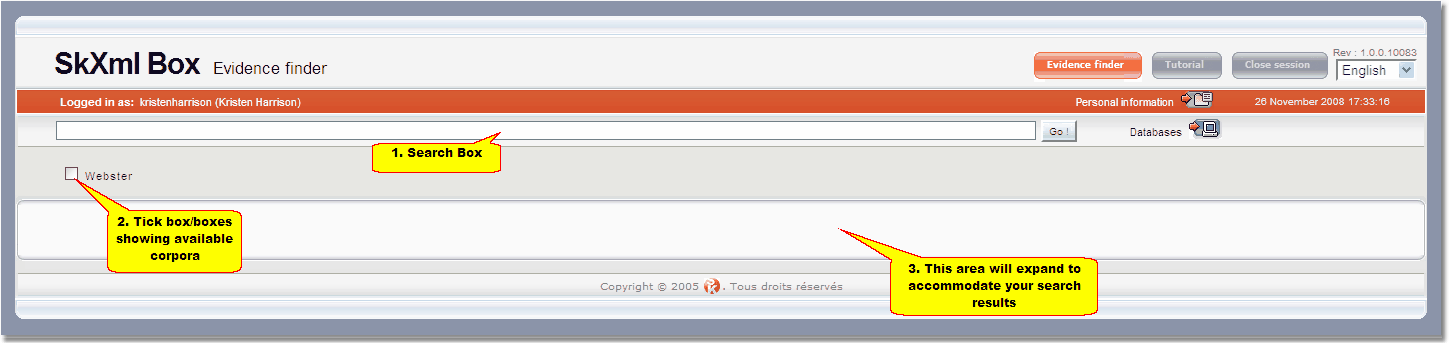 |
The SkXML search screen consists of three parts:
| 1) | Search box: this is where you type your query using the SkXML language. The Go! button to the right of this box executes this query. |
| 2) | Tickboxes: situated below the search box are a series of tickboxes, one for each available corpus. There is only one corpus (Webster) in the above screenshot because that is the only project loaded on the DPS demonstration server. These tickboxes can be hidden by clicking on the Databases button to the right of the search box. Clicking the Databases button again will re-display them. |
| 3) | Results area: the area at the bottom is where search results are displayed. |
To perform an SkXML search:
| 1) | Select the corpora you wish to search by ticking the appropriate tickboxes. |
| 2) | Use the Query builder or |
| 3) | Type your query into the text box and Press Return or click the Go! button. |
The SkXML language contains facilities to control how query results are displayed. If you do not use any of these, the default is to display the label of all entries that match your search: that is, all those entries whose contents meet your search criteria at least once.
In addition to viewing search results, the following options are available:
| • | Clicking the Edit link next to an entry causes that entry to be downloaded into the Entry Editor. This is the same function as the Quick Edit option on the search results screen. |
| • | If configured, clicking the Edit section link next to a search result, will download the first match point (=column) to your entry editor. This is especially useful if you're editing very big entries where it would otherwise be cumbersome and slow to first download the fuull entry and then find the relevant structure to edit. |
| • | Clicking the View link next to an entry causes that entry's contents to be displayed in a popup window. The format is the same as in the WYSIWYG view invoked from the search results screen. |
| • | Clicking the Summary button hides the matched entries and displays only a summary of the number of matches in each corpus. Click the Details button that appears in summary view to see the list of matched entries for a corpus. |
| • | Clicking the Print button prints a copy of the search results. |
| • | Clicking the Go to list module button loads the entries found into the search results screen. (The result is the same as you would have achieved by doing your SkXML search from the search screen.) |
| • | The Export button will export from the selected entries (select entries individually or use the select-all option) the selected columns (= match points, select individually). This will be saved as an .xml file. The file can be opened in the Entry editor if the extension is changed to .dpsxml file and then double clicked. This gives a good option of checking and looking at parts of entries - but note that whatever editing is done can not be saved back to the server and the entries are not locked. Any editing will have to be saved as a new xml file. |
The SkXML search language is quite complex so there's a query builder to help you:
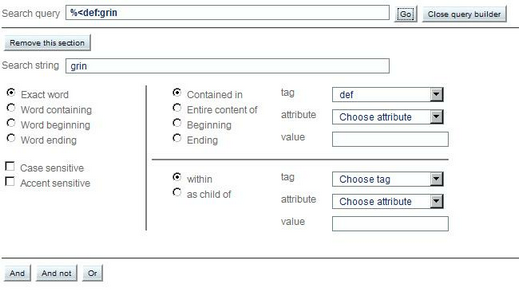
| 1. | You specify your search string: is it full words or beginning/end/middle of word? |
| 2. | Is it accent/case sensitive? |
| 3. | Specify the tag it should appear in if search should be restricted to this tag and add attribute and value if further restrict the appearance of the string |
| 4. | Should this tag may in turn be restricted to appear within another tag? |
| 5. | Add another condition as AND or OR or AND NOT. |
This query builder should be enough for most searches, but SkXML is more capable and to use that you will need to learn (or look up) the SkXML language below. The query builder will always be a good place to start and then you can add the bits that are not provided via the interface yourself directly in the search string that has been built up.
Having seen how to perform a search, it is high time to tackle the syntax of the SkXML query language - if you don't think you will have to do very sophisticated searches from the start, you can skip this section and return if your needs change.
![]() Note: this is quite a complex topic, and is best tackled when you are feeling confident.
Note: this is quite a complex topic, and is best tackled when you are feeling confident.
Specifying Words
SkXML searches for words, not for individual characters: searching for 'a' will find the word 'a', but not words that contain the letter 'a'. However, the language contains sophisticated wildcard facilities – usually known as regular expressions – that overcome this apparent limitation; the trick is to make sure that your combination of letters and regular expressions defines a whole word, not just part of a word. (Note that SkXML treats punctuation as words. The text 'me; but' is treated as three words: 'me', ';', and 'but'.)
The following 'building blocks' can be used to specify a word:
This... |
...will match |
Examples |
<letter or number> |
itself |
a will match the letter "a", b will match "b", etc.; thus, "back" will match the word "back". |
[<set of characters>] |
any character in <set of characters> |
b[ae]ck will match "back" or "beck"; b[a-d]ck will match "back", "bbck", "bcck", or "bdck". |
. |
any letter |
hel. will match “held”, “hell”, “helm”, etc. |
? |
the previous item zero or one time |
hello? will match “hell” or “hello”; =hell[oa]? will in addition match "hella". |
* |
the previous item zero or more times |
hello* will match “hell”, “hello”, “helloo”, “hellooo”, etc.; hell.* will match any word beginning with "hell": for example, “hello” or “hellos”; .* will match any word. |
+ |
the previous item one or more times |
hello+ will match “hello”, “helloo”, “hellooo”, etc., but not "hell". |
(<items>) |
treats <items> as if they are a single item |
hel(lo)* will match “hel”, “hello”, “hellolo”, “hellololo”, etc. |
(<first>|<second>) |
either <first> or <second> |
cent(re|er) will match "centre" or "center". |
\<any character> |
itself |
\$ will match the character "$", \* will match "*", etc. (Note that the \ cancels the normal special meaning of *.) In general, non-alphanumeric characters must be preceded by \. |
In the remainder of this description of the SkXML language, the term word is used to mean a word as specified using letters, regular expressions, or both.
Case- and Accent- Sensitivity
The rules given above aren't quite truthful: by default, letters are matched case- and accent-insensitively, so any letter or regular expression that will match 'a' will also match 'A', 'á', 'Á', etc. The following flags qualify whole words to control how they are matched:
This... |
...will match |
cast |
(Default case) the word “cast”, case- and accent-insensitive: "Cast" and "cást" will also match. |
&cast |
the word “cast”, accent-sensitive: "cást" will no longer match. |
#cast |
the word “cast”, case-sensitive: "Cast" will no longer match. |
&#cast |
the word “cast”, case- and accent-sensitive: "Cast" and "cást" will no longer match. |
Inflections and Compounds
The following flags indicate that common variants of the specified word should also be matched:
This... |
...will match |
b[ie]g@ |
"beg" or "big" plus inflections ("begs", "begging", "bigger", "biggest"). & and # qualifiers are ignored if @ is specified. |
horn--rimmed |
optional hyphen: matches "horn-rimmed", "hornrimmed", and "horn rimmed". |
o''clock |
optional apostrophe: matches "o'clock", "oclock", and "o clock". |
If a word is a number, various numerical qualifiers are available:
This... |
...will match |
Examples |
<number> |
the number <number> |
10 will match "10", 20 will match "20", etc. |
<<number> |
any number smaller than <number> |
<10 will match "9", "8", "7", etc. |
><number> |
any number greater than <number> |
>10 will match "11", "12", "13", etc. |
<=<number> |
any number smaller than or equal to <number> |
<=10 will match "10", "9", "8", "7", etc. |
>=<number> |
any number greater than or equal to <number> |
>=10 will match "10", "11", "12", "13", etc. |
Two qualifiers can be combined: >5<=10 will match '6', '7', '8', '9' and '10'.
Sequences and Proximity
We now have a powerful syntax for matching single words. SkXML can also be instructed as to how two or more words should relate to each other. As you would expect, a simple string of words matches itself: &#timeo &#Danoas &#et &#dona &#ferentes will match 'timeo Danaos et dona ferentes' (Virgil, Aeneid, ii.49). Other options are:
This... |
...will match |
cast ; shadow |
the words "cast" and "shadow" if occurring in the same XML element and within 20 words of each other, in any order. |
cast ;<number> shadow |
as above, but within <number> words: for example, cast ;50 shadow. |
case ;; shadow |
the words "cast" and "shadow" if occurring in the same XML element, within 20 words of each other, and in the specified order. |
cast ;;<number> shadow |
as above, but within <number> words: for example, cast ;;50 shadow. |
Note the spaces before and after the ;, ;;, etc.
A sequence of words specified with this syntax is called a 'Phrase'. If a phrase is preceded by ~, it will be matched even if some of its component words occur in sub-elements.
Boolean Operations on Phrases
This... |
...will match |
<phrase 1> | <phrase 2> |
if either <phrase 1> or <phrase 2> occur in the same entry |
<phrase 1> , <phrase 2> |
if both <phrase 1> and <phrase 2> occur in the same entry. |
Again, note the spaces before and after the | and ,.
XML Elements
Matches can also be limited to specific XML elements:
This... |
...will match |
<q |
the XML element "q", including its opening tag, content, and closing tag. |
<q:coin |
an XML element "q" with the word “coin” in its textual content (at any level). |
<q=coin |
an XML element "q" whose textual content is exactly the word “coin” (at any level). |
<q:(cast a shadow) |
an XML element "q" with the phrase “cast a shadow” in its textual content (at any level). |
<q:(^cast a shadow) |
an XML element "q" with the phrase “cast a shadow” at the start of its textual content (at any level). |
<q:(cast a shadow$) |
an XML element "q" with the phrase “cast a shadow” at the end of its textual content (at any level). |
<q:(^cast a shadow$) |
an XML element "q" with the phrase “cast a shadow” as its textual content (at any level). This is equivalent to <q=(cast a shadow) |
<!q:coin |
the word “coin”, but not in an XML element "q". |
<((?!q.*).)*:(/coin) |
An element which is NOT "q" containing the word "coin" |
<q:((?!coin.*).)* |
An element "q" which contains a word that is NOT "coin" |
<q:<w |
an XML element "q" that contains an element "w" at any level. |
<q:(/<w) |
an XML element "q" that contains an element "w" as its immediate child. |
<q@id |
an XML element "q" that has an attribute "id" |
<q@id:12 |
an XML element "q" that has an attribute "id" whose value contains the word "12". |
<q@id=12 |
an XML element "q" that has an attribute "id" whose value is exactly the word "12". |
Here are some examples to show how these basic operations can be combined:
This... |
...will match |
<q:<w:temp*. |
an XML element "q" that contains an element "w" that contains a word starting with "temp". |
<w@a:12:toto |
an XML element "q" with: (i) an attribute "a" whose value contains the word "12"; and (ii) the word "toto" in its textual content. |
<w@(a:12, b=42):toto |
as above, but additionally with: (iii) an attribute "b" whose value is "42". |
Count Filters
The number of times a word or XML element must appear can be specified by appending {{<occurrence filter>}}, where <occurrence filter> is an expression consisting of numbers and numerical qualifiers (see above, Numbers).
This... |
...will match |
help{{3}} |
all instances of the word "help" in an entry where it occurs exactly three times. |
help{{<3}} |
all instances of the word "help" in an entry where it occurs at least once but less than three times. |
<example:(help{{3}}) |
an XML element "example" that contains exactly three instances of the word "help". |
(<example:help){{3}} |
all instances of the word "help" within an XML element "example" in an entry where this occurs exactly three times. |
<example:(<q{{>3}}) |
an XML element "example" that contains at least four "q" elements. |
![]() Important note: precise positioning of parentheses is very important!
Important note: precise positioning of parentheses is very important!
The similar [[<occurrence filter>]] filter specifies which instances to match:
This... |
...will match |
help[[0]] |
the first instance of the word "help" in an entry. |
help[[3]] |
the fourth instance of the word "help" in an entry. |
help[[>3]] |
the fourth, fifth, sixth, seventh, etc., instances of the word "help" in an entry. |
help[[<3]] |
the first, second, and third instances of the word "help" in an entry. |
Note that the first instance is '0', not number '1'.
These two filters can be combined:
This... |
...will match |
help{{3}}[[0]] |
the first instance of the word "help" in an entry that has exactly three instances. |
help{{>5}}[[<2]] |
the first and second instances of the word "help" in an entry that has six or more. |
We give two versions: simple and more elaborate which uses brackets: using brackets is necessary if you want to combine things.
This... |
...will match |
<X<<<comment or <X@(<<(<comment)) |
A tag X with an annotation |
<X<<<comment:<topic:Y or <X@(<<(<comment:<topic:Y)) |
A tag X with an annotation with topic Y |
<X<<<comment:<text:Y or <X@(<<(<comment:<text:Y)) |
A tag X with an annotation with text containing Y |
<X<<<comment@status:Y or <X@(<<(<comment@status:Y)) |
A tag X with an annotation with status Y |
<X<<<comment@user:Y or <X@(<<(<comment@user:Y)) |
A tag X with an annotation by user Y |
<X@(type:Y,<<(<comment)) |
A tag X with attribute @type:Y and with an annotation |
<%X<<<%comment or <%X@(<<(<%comment)) |
To display the comment, you need to also display the annotated element itself |
<%X<<<comment:<%text or <%X@(<<(<comment:<%text)) |
To display the text of a certain annotation |
You will recall that, by default, SkXML displays the entry label of all entries in which one or more matches of your query were found but does not show the matches themselves. To show the matches you must specify a so-called "match point" in your query, using the % operator. The position of the % is important: the word or XML element immediately following is colour-coded and used as the focus of a keyword-in-context display. Let's see some examples:
The SkXML query %albatross might produce results like this:
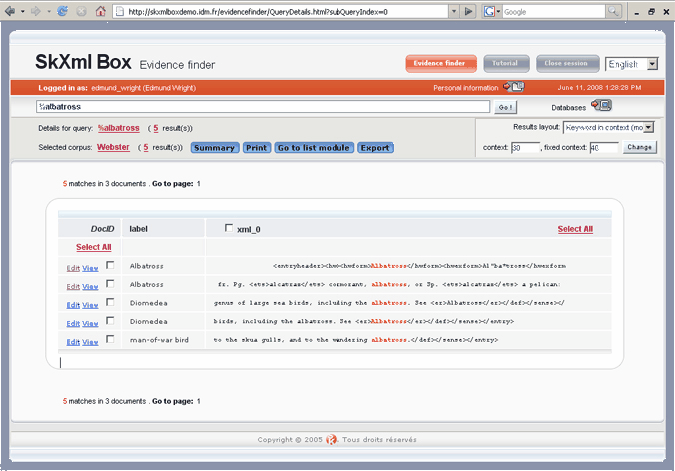 |
| Click to enlarge |
and the query %<def:albatross might produce results like this:
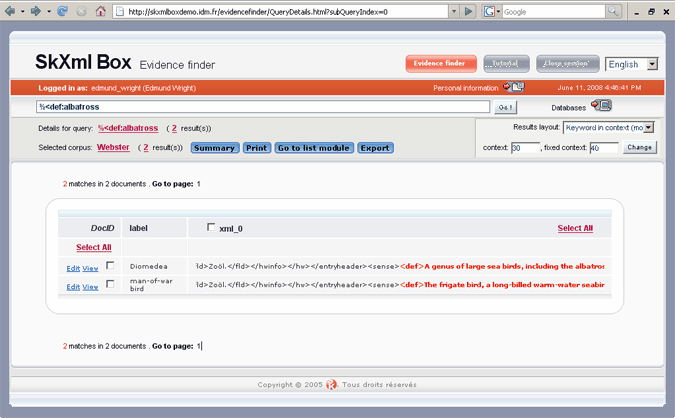 |
| Click to enlarge |
![]() Note in this example that the XML tagging is included in the match point. If you want to include just the content, specify <%def:albatross.
Note in this example that the XML tagging is included in the match point. If you want to include just the content, specify <%def:albatross.
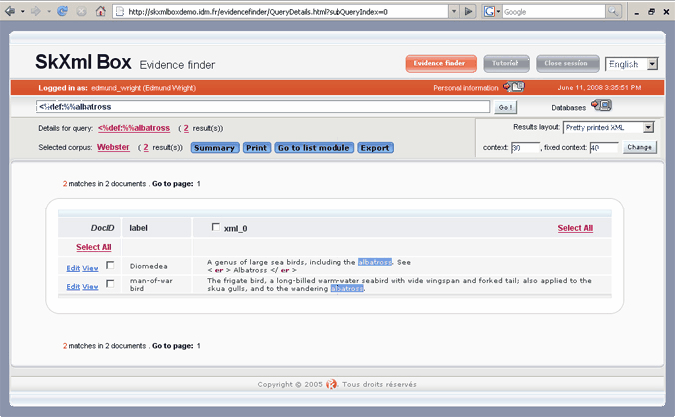
If the match point is an XML element, you can further highlight significant words or phrases within it. The query <%def:%%albatross might produce results like this:
 |
| Click to enlarge |
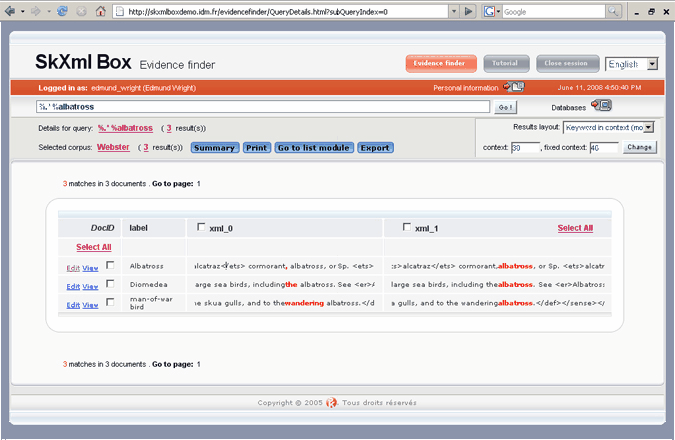
You can specify more than one match point in a single query, in which case SkXML will create a separate display column for each match point. The query %.* %albatross might produce results like this:
 |
| Click to enlarge |
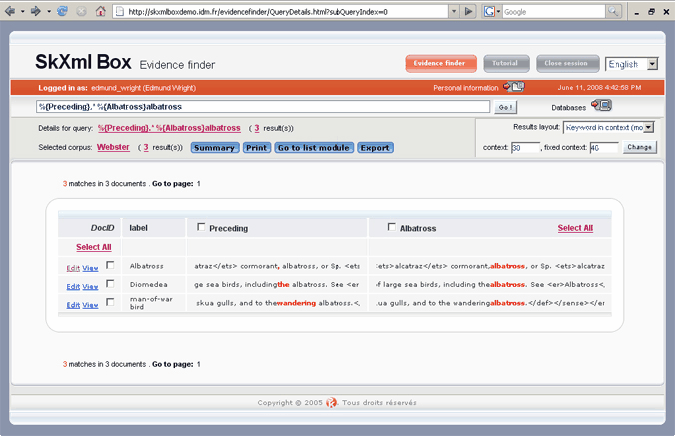
The default column names (xml_0, xml_1) can be replaced by names you specify; for example, %{Preceding}.* %{Albatross}albatross:
 |
| Click to enlarge |
Controlling the Keyword-in-Context View
The Results layout list-box (top right of the screen) offers two keyword-in-context views:
| 1) | keyword in context (monospace): The default, which uses a monospaced font to ensure correct text alignment. |
| 2) | keyword in context (mozilla/firefox): Uses special capabilities in Firefox to align text correctly using a proportionally spaced font. Note that this option is only configured for Firefox, so it will not work correctly in other browsers. |
The amount of context shown before and after the match point can be varied by adjusting the context and fixed context settings.
Click the Change button to apply your changes.
The Results layout list-box offers two other options:
| 1) | Petty printed XML Colour-codes and formats XML markup (elements, attributes, etc.) for easy reading. |
| 2) | Raw XML The same as pretty printed XML, except that no special formatting is applied to XML markup. |
![]() Note: that these XML views do not show any context.
Note: that these XML views do not show any context.